
Event tracking is one of the first systems implemented in a mobile app, and one of the last to be questioned when things go wrong. Dashboards populate quickly, metrics start flowing, and teams gain a sense of visibility that feels reliable. For a while, it works.
But as the product evolves, something subtle begins to shift. Numbers stop aligning across dashboards, funnels show inconsistent drop-offs, and different teams interpret the same metric differently. The issue is rarely obvious, yet it compounds over time.
The problem is not that tracking stops working. It is that it was never designed to scale. What begins as instrumentation gradually becomes infrastructure, but without the discipline required to support that transition.
Event tracking does not fail suddenly. It degrades quietly until no one fully trusts the data.
What Event Tracking Actually Means in Practice
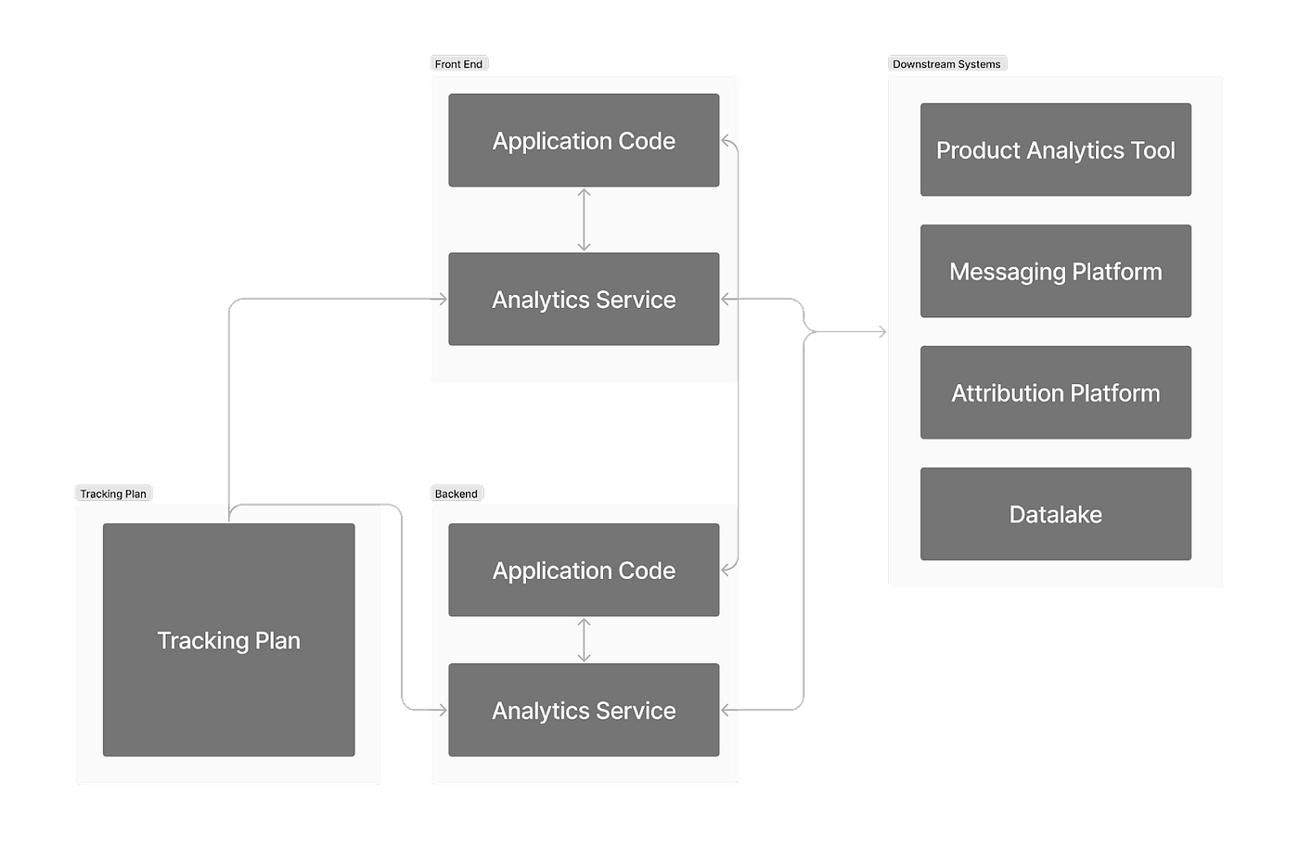
At a surface level, event tracking is the process of capturing user actions within an app. These actions, such as opening a screen, completing a purchase, or interacting with a feature, are recorded along with contextual data that helps explain them.
In practice, event tracking is the foundation of how a product understands itself. Every funnel, retention curve, cohort analysis, and experiment relies on the assumption that these events are accurate and consistent.
A typical event structure includes three layers:
| Component | Role in Tracking System | Example |
|---|---|---|
| Event | The action performed | checkout_started |
| Properties | Contextual details of the action | cart_value, item_count |
| User Attributes | Persistent user-level information | user_id, plan_type |
This structure seems simple, but its consistency determines whether analytics remains usable as the system grows.
Why Most Tracking Systems Fail Over Time
Tracking systems rarely break because of a single mistake. They fail because of accumulation. Each new feature introduces new events, each team adds tracking independently, and over time, the system loses coherence.
Initially, these inconsistencies appear harmless. A slightly different event name or an extra property does not seem critical. However, as these differences multiply, they begin to distort the overall picture.
Three patterns consistently emerge in failing tracking systems:
- Similar user actions are tracked under different names
- Properties are inconsistently defined or reused incorrectly
- No shared understanding exists of what events actually represent
The result is not missing data, but conflicting data. And conflicting data is significantly more dangerous because it creates false confidence.
Designing an Event Schema That Survives Scale
A scalable tracking system begins with a well-defined event schema. This schema acts as a contract, ensuring that every event follows a consistent structure regardless of who implements it.
The most important principle in schema design is to model events around user intent rather than interface interactions. Interfaces change frequently as products evolve, but user intent remains relatively stable.
This distinction becomes clear in practice:
| UI-Based Tracking | Intent-Based Tracking |
|---|---|
| button_clicked | checkout_started |
| page_opened | product_viewed |
| icon_tapped | item_saved |
When events are tied to UI elements, every redesign introduces tracking changes. When they are tied to intent, the system remains stable even as the product evolves.
A strong schema also enforces clarity between events, properties, and user attributes. Without this separation, data becomes difficult to interpret and reuse across analyses.
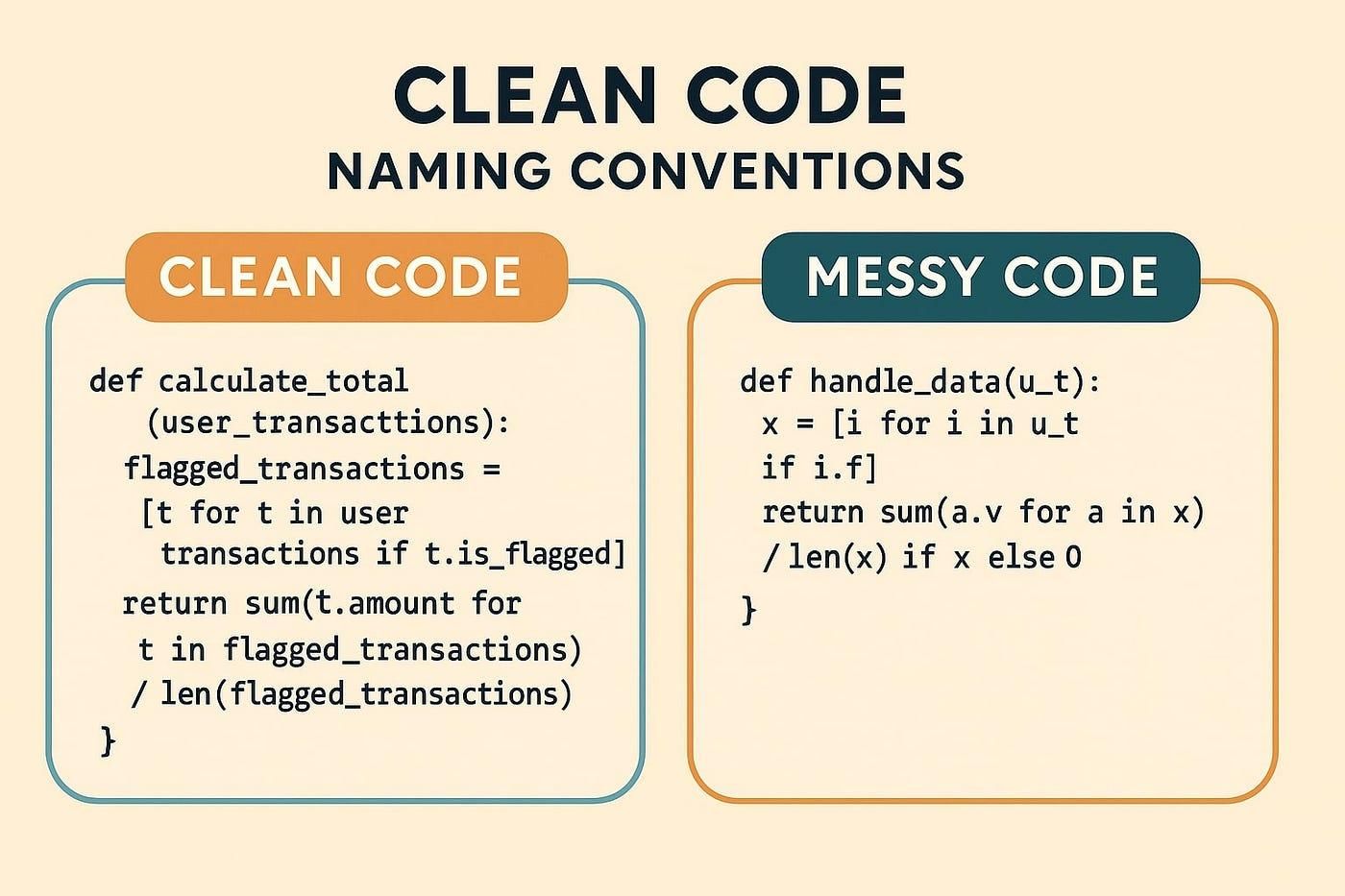
Naming Conventions and the Cost of Inconsistency
Naming is often underestimated in tracking systems, yet it is one of the primary sources of long-term issues. Poor naming decisions create ambiguity, and ambiguity directly reduces the reliability of analysis.
Inconsistent naming introduces friction at every stage, from querying data to building dashboards. Over time, teams begin to rely on tribal knowledge rather than shared definitions.
The difference between poor and effective naming is not subtle:
| Poor Naming | Issue | Improved Naming |
|---|---|---|
| click | No context | product_clicked |
| submit | Ambiguous | signup_submitted |
| screen1_open | Not scalable | home_opened |
Effective naming follows a consistent pattern, remains descriptive without being verbose, and reflects user intent rather than implementation details.
A well-named event explains itself. A poorly named event requires documentation.
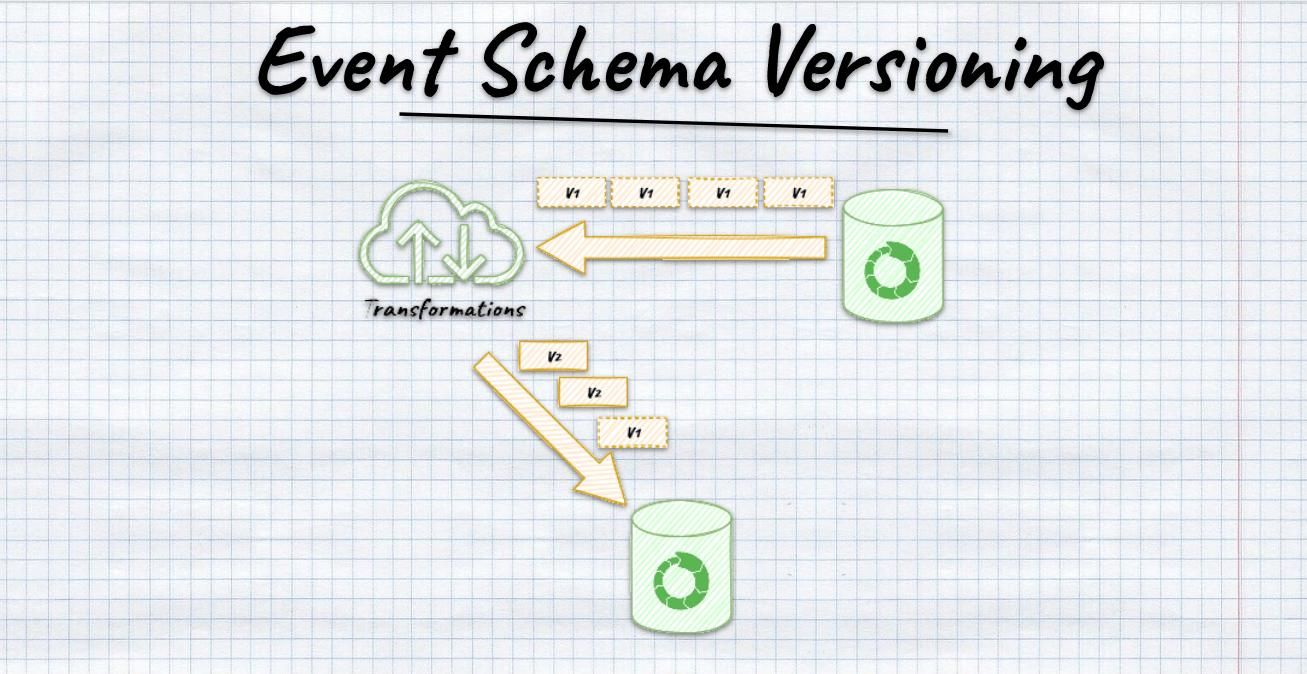
Versioning and the Problem of Evolving Products
No product remains static, and neither does its tracking system. Events evolve as features change, new properties are added, and definitions are refined. Without proper versioning, these changes introduce inconsistencies that break historical comparisons.
This phenomenon, often referred to as schema drift, creates situations where the same event represents different meanings across time. As a result, trends become unreliable and insights lose credibility.
Consider a simple evolution:
| Version | Event Name | Properties Included |
|---|---|---|
| v1 | checkout_started | cart_value |
| v2 | checkout_started | cart_value, coupon_code |
Without explicit versioning or documentation, analysts may unknowingly combine incompatible datasets. This leads to incorrect conclusions that are difficult to detect.
Versioning strategies should balance clarity and continuity. In some cases, introducing a new versioned event is necessary. In others, backward compatibility can preserve consistency.
Tracking Debt: The Hidden Layer of Analytics Failure
Tracking debt is the accumulation of inconsistencies, unused events, undocumented changes, and broken properties within a tracking system. Unlike technical debt, it is rarely visible in code, but its effects are felt across the organization.
As teams grow and development accelerates, tracking debt builds silently. Events are added without review, outdated ones are never removed, and documentation falls behind implementation.
Over time, this leads to a system where:
- Events exist but their purpose is unclear
- Multiple events represent the same action
- Teams no longer trust the data they rely on
Tracking debt does not slow down development. It slows down understanding.
The longer it remains unaddressed, the harder it becomes to fix, as dependencies across dashboards and analyses increase.
Data Quality, Validation, and Observability
A scalable tracking system does not rely solely on design. It requires continuous validation and monitoring to ensure that data remains accurate over time.
Tracking should be treated with the same rigor as any production system. This includes validating events before release, monitoring them after deployment, and detecting anomalies early.
A robust system typically includes:
- Pre-release validation to ensure correct implementation
- Real-time monitoring of event flow and anomalies
- Alerts for missing or malformed data
Without observability, tracking issues often go unnoticed until they affect critical metrics. By that point, the cost of correction is significantly higher.
How Poor Tracking Corrupts Decision-Making
The most dangerous outcome of poor tracking is not missing data, but misleading data. When metrics appear reliable but are fundamentally flawed, they lead teams toward incorrect decisions.
This impact is most visible in key areas:
Funnels become unreliable.
Steps may be missing or inconsistently tracked, making it impossible to identify true drop-offs.
Metrics lose meaning.
Different definitions of the same event lead to conflicting reports, reducing confidence in analysis.
Trust erodes across teams.
When data cannot be trusted, teams revert to intuition, undermining the purpose of analytics entirely.
Bad data does not just obscure reality. It reshapes it in ways that are difficult to detect.
Building a Tracking System That Scales With the Product
A scalable tracking system requires more than good intentions. It requires structure, ownership, and discipline across the entire lifecycle of the product.
Governance plays a central role in maintaining consistency. Clear ownership ensures that tracking decisions are reviewed, standardized, and aligned with the broader system.
Documentation acts as the shared language of the system. An event catalog that defines each event, its properties, and its purpose becomes essential as teams grow and collaboration increases.
Validation ensures that what is designed is actually implemented correctly. Without it, even well-defined schemas can fail in practice.
Finally, tooling and automation reduce reliance on manual processes. Schema enforcement, automated checks, and anomaly detection create guardrails that maintain consistency over time.
Together, these elements transform tracking from a fragmented implementation into a reliable system.
Conclusion: From Instrumentation to Infrastructure
Event tracking begins as a simple layer of instrumentation, but as products scale, it becomes a critical part of decision-making infrastructure. This transition requires a shift in how tracking is approached.
It is no longer sufficient to ask what should be tracked. The more important question is how tracking is designed, maintained, and evolved over time.
A well-designed tracking system does not just collect data. It preserves meaning, ensures consistency, and enables teams to trust the insights they rely on.
In an environment where every decision depends on data, that trust is not optional. It is foundational.


