
TL;DR: Most teams assume test automation scales with more tests, but at scale flakiness, maintenance, and noise grow faster than value. Automation doesn’t fail because of tools, it fails because of poor prioritization, which is why high-performing teams focus on fewer, high-impact tests instead of more coverage.
In the early stages of a product, automation feels like leverage. A small suite of tests runs quickly, feedback loops are tight, and failures are easy to interpret. Teams gain confidence because every test has a clear purpose and every failure signals something meaningful.
That clarity does not survive scale. As the application grows, the test suite expands faster than the product itself. Execution slows down, failures become harder to trust, and debugging consumes more time than development. What once accelerated delivery begins to quietly delay it, and the shift is gradual enough that most teams do not notice it happening. Instead of enabling speed, automation starts shaping how work is done, often forcing teams to adapt to the test suite rather than the product.
The False Promise of Early Automation Success
Automation succeeds early because the system is simple. There are fewer dependencies, fewer edge cases, and fewer environments to consider. Tests are written against stable assumptions, and those assumptions hold long enough to create a sense of reliability. In this phase, even poorly designed tests can appear effective because the system itself is predictable.
The mistake teams make is treating this phase as a blueprint. Scaling from fifty tests to thousands is not a matter of volume. It introduces new layers of complexity including asynchronous behavior, device fragmentation, and integration dependencies. Each new layer increases the chances of failure in ways that are not always visible or easy to diagnose.
Automation does not fail because teams do it incorrectly. It fails because the conditions under which it succeeds no longer exist. What worked in a controlled, predictable environment is now operating in a system filled with variability. Without rethinking the strategy, teams end up scaling assumptions instead of scaling reliability, and that gap is where most automation setups begin to break down.
Flaky Tests Are a System Signal, Not a Test Problem
Flaky tests are often dismissed as noise, but they are one of the clearest indicators of systemic instability. When a test passes and fails under the same conditions, it reveals hidden dependencies that are not being controlled. These dependencies may include timing issues, network variability, inconsistent state management, or even race conditions that only appear under specific circumstances.
The real issue is not the test itself, but the environment and system behavior it exposes. Flakiness tends to increase as systems become more distributed and asynchronous, making failures harder to reproduce and diagnose. What looks like randomness is often a lack of determinism in the system.
Over time, teams adapt to flakiness in ways that weaken the entire testing process. Tests are rerun until they pass, failures are deprioritized, and unstable cases are ignored or quarantined. This creates a pattern where tests still exist, but their outcomes lose meaning, and real issues can slip through unnoticed.
When teams stop trusting their tests, automation stops being a safety net and starts becoming noise.
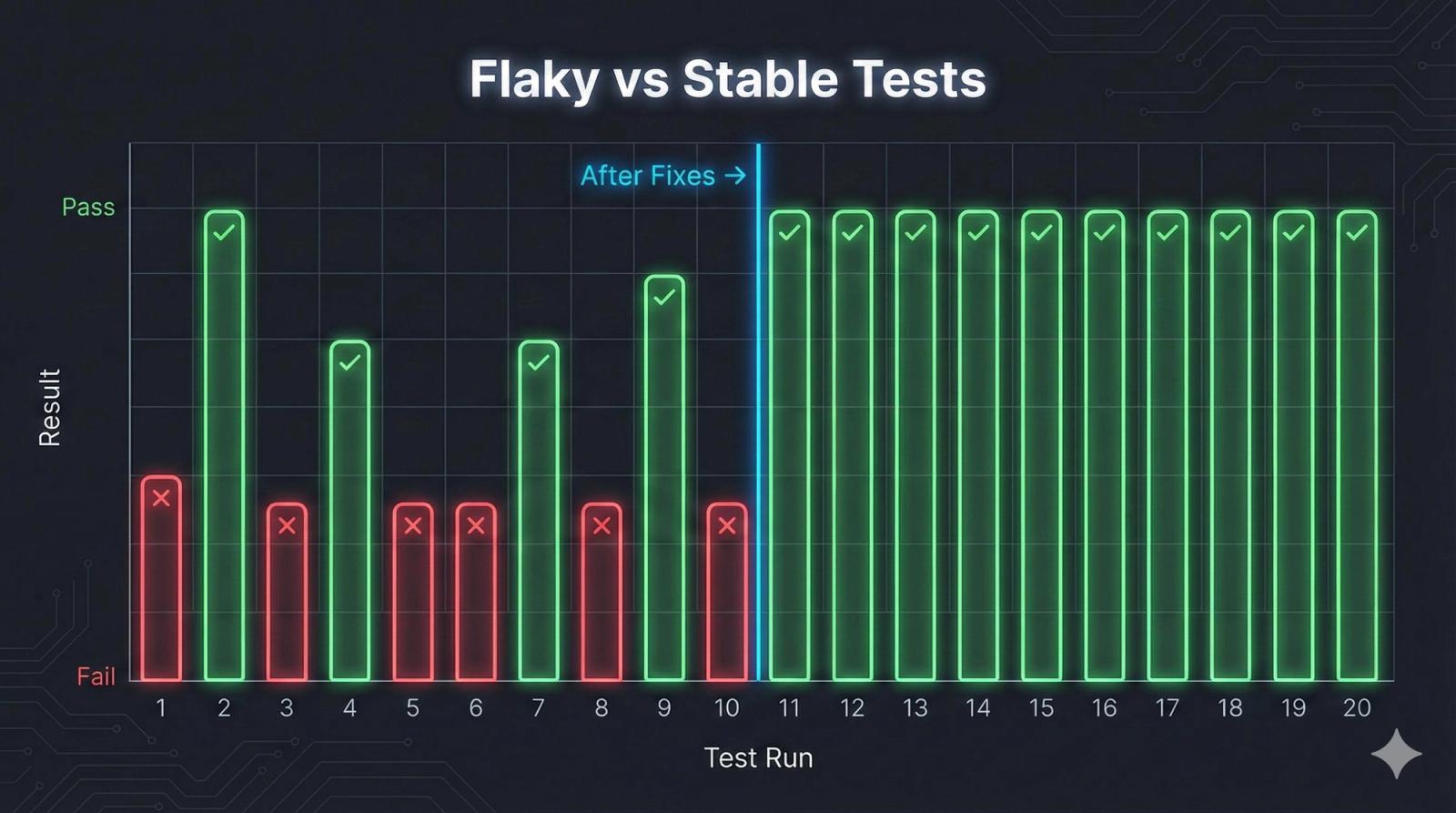
Environment Instability Is Built Into Mobile Systems
Mobile applications operate in environments that are inherently unpredictable. Devices vary in hardware capabilities, operating systems evolve continuously, and network conditions fluctuate in real time. Even backend services introduce variability that cannot be fully controlled during testing.
Automation assumes repeatability, but mobile ecosystems resist it. A test that passes in one environment may fail in another without any change in the underlying code. As coverage expands across devices and configurations, this instability compounds and becomes harder to isolate.
| Source of Instability | Impact on Automation | Long-Term Effect |
|---|---|---|
| Device fragmentation | Inconsistent behavior across devices | Increased flaky tests |
| Network variability | Delayed or failed API responses | False negatives |
| OS updates | UI or permission changes | Broken test flows |
| Third-party services | External dependency failures | Unpredictable outcomes |
This is not an edge case. It is the default condition under which mobile automation operates.
Maintenance Is the Real Cost of Automation
Execution is visible, but maintenance is what defines the sustainability of an automation strategy. Every UI change, API update, or flow modification introduces the possibility of test breakage. Over time, the effort required to keep tests functional grows faster than the effort required to build the product itself. What starts as a one-time investment quietly turns into a continuous cost.
Teams often underestimate how quickly this cost accumulates. A small change in a selector or interaction pattern can cascade into dozens of failing tests. Fixing them requires context, time, and coordination across teams, which slows down development and creates friction in release cycles. As the system evolves, maintaining stability in tests becomes an ongoing challenge rather than an occasional task.
This leads to a subtle but critical shift. Engineers are no longer building features with tests as support. They are maintaining tests as a parallel system that competes for the same resources. The more the suite grows, the more effort is required just to keep it from breaking.
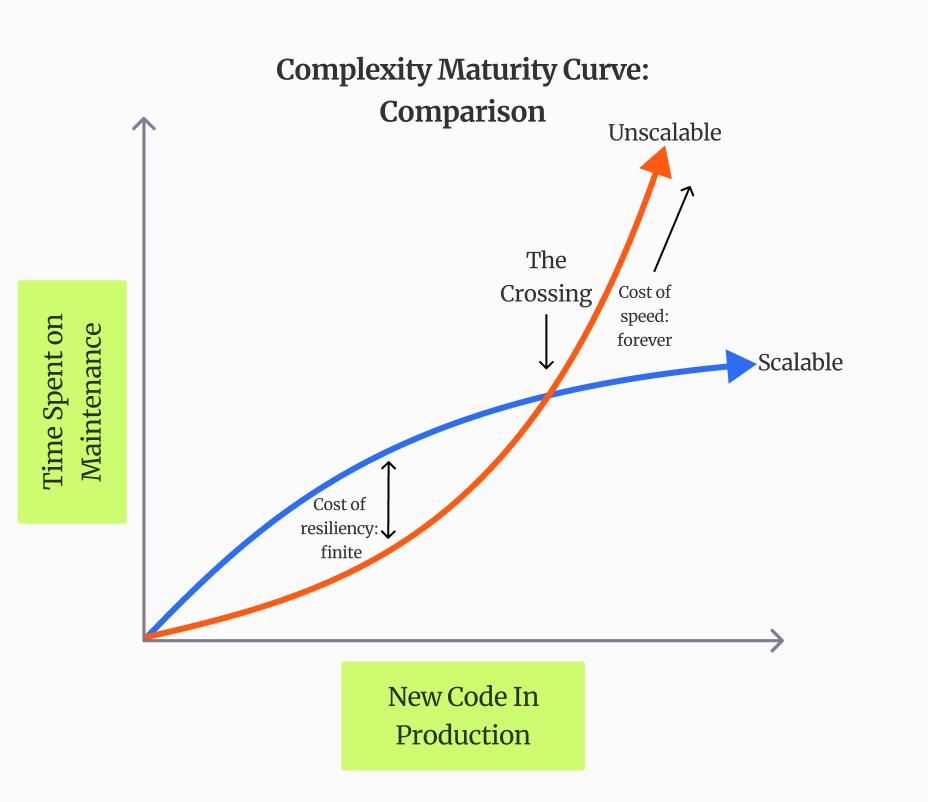
When Automation ROI Turns Against You
Automation is expected to improve speed and reliability, but beyond a certain point it begins to deliver diminishing returns. Each additional test adds execution time and increases the surface area for failure, while contributing less incremental value. Instead of improving confidence, the system starts introducing delays and uncertainty.
The shift from positive to negative ROI is not always obvious, but it can be identified through patterns:
- Release cycles become slower despite increased test coverage
- Failures are investigated less frequently because they are often unreliable
- Test maintenance consumes a significant portion of engineering time
At this stage, automation is no longer reducing risk. It is redistributing it in less visible ways, where delays, ignored failures, and hidden instability begin to affect overall product quality.
Manual Testing Still Plays a Critical Role
Manual testing continues to be relevant because it addresses a dimension of quality that automation cannot fully capture. Human testers bring context, intuition, and adaptability to the process. They can question assumptions, explore unexpected paths, and notice subtle issues in usability or performance that scripted tests are not designed to detect.
Automation is effective at validating known scenarios where outcomes are predictable and repeatable. Manual testing, on the other hand, is effective at discovering unknown issues that emerge from real user behavior. This includes edge cases, inconsistent flows, and experience gaps that only become visible through exploration rather than predefined steps.
Removing manual testing does not streamline the process. It reduces visibility into real-world usage. A balanced approach recognizes that manual testing is not a fallback for when automation fails. It is a complementary layer that strengthens the overall testing strategy by covering areas automation cannot reliably reach.
Traditional Automated Testing Remains Powerful but Fragile
Script-based frameworks provide deep control and flexibility, allowing teams to build testing systems tailored to their application. This makes them highly effective for validating complex workflows and integrating directly into CI/CD pipelines. In controlled conditions, they offer consistency and speed that manual testing cannot match.
Tools like Appium enable cross-platform automation and extensive customization, but they also require continuous engineering effort to maintain. As applications evolve, even small changes in UI or logic can break multiple tests, creating a constant cycle of updates and fixes.
The challenge is not in building automation. It is in keeping it stable as the system evolves. What begins as a structured and reliable setup can gradually become fragile if maintenance is not actively managed, making long-term scalability the real concern rather than initial implementation.
AI-Driven Testing Introduces a New Layer of Abstraction
AI-driven testing aims to reduce the burden of maintaining automation. Features such as self-healing tests and automated test generation promise to adapt to changes without requiring constant manual updates.
These capabilities provide measurable improvements, especially in reducing minor breakages caused by UI changes. However, they do not eliminate the need for thoughtful test design. AI can adjust how tests behave, but it cannot fully understand what should be tested or why.
AI reduces effort, but it does not replace judgment.
In many cases, AI shifts complexity rather than removing it. Teams spend less time fixing scripts, but more time validating whether AI-generated behavior is correct and meaningful.

Platform-Based Automation: Convenience with Tradeoffs
To reduce the burden of building and maintaining infrastructure, many teams turn to platform-based solutions. These platforms abstract device management, execution environments, and sometimes even test creation itself.
They simplify adoption and accelerate setup, but they do not remove the underlying challenges of automation. Instead, they relocate those challenges into a managed environment.
LambdaTest: Scalable Infrastructure Without Ownership
LambdaTest provides access to a wide range of devices and environments through the cloud, allowing teams to run tests across multiple configurations without maintaining physical infrastructure. This is particularly valuable for teams that need broad coverage but lack the resources to manage it internally.
The primary advantage lies in scalability. Tests can be executed in parallel across devices, significantly reducing execution time. However, this scale introduces its own complexity. Debugging failures in distributed environments can be slower, and identifying root causes often requires deeper investigation into logs and session data.
LambdaTest reduces operational overhead, but it does not simplify the logic of testing. The complexity shifts from infrastructure management to result interpretation.
Maestro: Simplicity Through Abstraction
Maestro focuses on reducing the effort required to write and maintain test scripts. Its low-code approach allows teams to define flows in a more readable and concise format, making it accessible to a broader range of contributors.
This simplicity is effective for straightforward user journeys and stable interfaces. It lowers the barrier to entry and accelerates test creation. However, as applications grow in complexity, abstraction can become a limitation. Custom scenarios, dynamic interactions, and edge cases may require workarounds that reintroduce complexity.
Maestro simplifies the surface layer of automation, but deeper system behavior still demands careful handling.
Quash: Faster Debugging and Issue Reproduction
Quash approaches testing from a different angle by focusing on debugging and issue resolution rather than just execution. It emphasizes capturing detailed context around failures, enabling teams to reproduce and fix issues more efficiently.
This focus addresses one of the most time-consuming aspects of automation, which is understanding why a test failed. By providing clearer insights into failures, Quash helps reduce the time between detection and resolution.
However, improving debugging does not eliminate failures themselves. Flakiness and instability can still occur, and their root causes still need to be addressed within the system. Quash accelerates the response to issues, but it does not remove their existence.
Appium: Flexibility With Full Responsibility
Appium represents a different category within platform-based discussions because it provides flexibility without abstraction. It allows teams to build highly customized automation frameworks that integrate deeply with their systems.
This level of control is powerful, especially for complex applications with unique requirements. However, it comes with full ownership of maintenance, infrastructure, and stability. Every improvement must be implemented and sustained by the team.
Appium does not impose constraints, but it also does not provide guardrails. Success depends entirely on how well the system is designed and maintained.
Despite the differences between platforms, the underlying challenges remain the same. The real issue is not which tool is used, but how automation is applied.
Rethinking Automation: Strategy Over Tools
By this point, the pattern becomes clear. Automation does not fail because of tools alone. It fails when it is applied without clear prioritization.
Too Much Automation in the Wrong Places
Most automation strategies fail not because of tools, but because of poor prioritization. Teams tend to automate everything they can, instead of focusing on what actually matters.
Low-impact scenarios often get automated alongside critical user flows. This leads to large test suites that generate frequent failures, but not always meaningful ones. Over time, the signal gets diluted, and teams spend more time managing noise than improving quality.
Automation should not be measured by coverage alone. Its effectiveness depends on how well it aligns with real user risk and business impact.
A More Sustainable Approach to Testing
Scaling testing requires a shift from volume to intent. Instead of maximizing coverage, teams need to focus on meaningful coverage that delivers consistent value.
High-impact and stable workflows should be automated because they provide reliable feedback. Areas that are unstable or frequently changing are better handled through manual or exploratory testing. AI and platforms can reduce effort, but they should support decisions, not replace them.
A sustainable testing strategy is built on control, prioritization, and clarity. It is not about doing more automation, but about doing the right automation.
Not all tests need to run all the time. High-performing teams prioritize test execution based on risk, recent changes, and critical user flows, instead of running entire suites blindly. This reduces feedback time while keeping coverage meaningful.
Conclusion: Automation Should Scale Confidence, Not Complexity
Automation rarely fails all at once. It slows down first. Tests become harder to trust, failures take longer to investigate, and maintenance begins to compete with development. By the time teams recognize the problem, automation is already adding more friction than it removes.
The issue is not the tools themselves, but the assumption that automation scales linearly. It does not. As test suites grow, complexity increases faster than value unless there is clear prioritization. Without that control, automation shifts from being a reliability layer to a source of overhead.
Sustainable testing is not about maximizing automation, but managing it intentionally. High-impact and stable scenarios should be automated, exploratory areas should remain manual, and AI or platforms should be used to reduce effort where it truly matters. The goal is not to eliminate complexity, but to ensure it is aligned with real product risk.
Teams that succeed at scale treat automation as a system that evolves with the product. They focus on signal over volume, reduce unnecessary coverage, and optimize for confidence rather than activity.
Automation should make development faster and more reliable. When it starts doing the opposite, the problem is not execution. It is strategy.
Further Reading and References
- Test Flakiness in Automation from Medium
- How to Scale Mobile Automation Testing Effectively on Applitools
- Manual vs Automated Testing: Where Each Actually Works from digia.tech
- Just Say No to End-to-End Tests at GoogleBlog
- The Practical Test Pyramid from martinfowler
Ready to ship in-app experiences without waiting on releases?
Book a Demo or See Digia in action