
TL;DR: 100% test coverage does not guarantee bug-free software. Coverage only shows that code was executed during testing, not that real-world behavior, integrations, edge cases, or failure scenarios were validated correctly. Reliable software comes from layered testing strategies, realistic scenario validation, observability, and risk-based testing rather than chasing coverage percentages alone.
For years, software teams have treated test coverage as a quality benchmark. Dashboards display percentages in green, CI pipelines celebrate high numbers, and engineering teams often associate 100% coverage with software reliability. On paper, it sounds logical. If every line of code is executed during testing, the application should be safe to release.
But production incidents continue to happen in systems with excellent coverage reports. Applications still crash, payments still fail, APIs still break, and user journeys still collapse under real-world conditions. The problem is not that coverage is useless. The problem is that coverage measures execution, not correctness.
A test can execute a line of code without proving that the behavior is actually correct. This distinction is where many teams develop false confidence. They optimize for a metric that looks reassuring while critical risks remain untested.
“Code coverage tells you what ran. It does not tell you what was validated.”
Understanding this difference is essential for building reliable software systems. Coverage is a signal, not proof of quality.
What Test Coverage Actually Measures
Test coverage is a metric that shows how much of the application code was executed during automated testing. Different types of coverage exist, including line coverage, branch coverage, function coverage, and statement coverage. Each one measures execution from a slightly different perspective.
| Coverage Type | What It Measures | Common Limitation |
|---|---|---|
| Line Coverage | Whether lines of code were executed | Does not verify logic correctness |
| Branch Coverage | Whether conditions took multiple paths | Can still miss edge cases |
| Function Coverage | Whether functions were called | Calling a function is not validating behavior |
| Statement Coverage | Whether statements executed | Weak indicator of real-world reliability |
Coverage became popular because it is measurable. Engineering leaders can track it over time, enforce thresholds in CI/CD pipelines, and use it as a visible indicator of testing discipline. Metrics create accountability, which is useful in large engineering organizations.
However, measurable does not always mean meaningful. A test suite can technically execute every line in the application while validating almost nothing important.
Consider this example:
function calculateDiscount(price, userType) {
if (userType === "premium") {
return price * 0.8;
}
return price;
}
A test could execute both branches and achieve full branch coverage without checking whether the returned values are actually correct. The code ran, but the business rule may still be broken.
That distinction changes everything.
Code Coverage vs Scenario Coverage
One of the biggest misconceptions in testing is assuming that code coverage automatically represents user coverage. It does not.
Code coverage focuses on whether the application code executed during tests. Scenario coverage focuses on whether real user situations were validated. These are entirely different ideas.
A checkout flow may have 100% backend coverage, but the real user journey could still fail because of:
- Payment gateway latency
- Session expiration
- Invalid promo code combinations
- Currency conversion issues
- Race conditions during inventory updates
- Mobile network interruptions
Imagine an e-commerce platform with 95% backend coverage on its checkout service. Unit tests validate pricing calculations, inventory updates, discount logic, and payment request generation successfully.
Yet users still report failed purchases during flash sales.
The issue turns out to be a race condition where inventory updates and payment confirmations occasionally execute out of order under high traffic. Every individual service technically passed its tests, but the complete workflow failed under production concurrency.
The code was covered. The real-world scenario was not.
This is why applications often pass automated pipelines but still fail under production conditions. Real users behave unpredictably. They refresh pages midway through workflows, switch devices, lose connectivity, retry actions repeatedly, and interact with the system in ways developers never anticipated.
Scenario coverage forces teams to think beyond implementation details. It shifts focus toward behavior, workflows, and system reliability under realistic conditions.

The False Confidence Problem
High coverage percentages can create psychological safety inside engineering teams. Once dashboards show 90% or 100% coverage, teams naturally assume risk has decreased significantly. In reality, the metric may simply reflect quantity rather than quality.
This often leads to shallow testing strategies where teams write tests mainly to satisfy coverage thresholds.
For example, developers sometimes create tests that:
- Execute functions without meaningful assertions
- Mock nearly every dependency
- Avoid complex workflows because they are harder to test
- Ignore failure states and edge cases
- Focus only on happy paths
The result is a green pipeline that hides actual weaknesses.
A particularly dangerous pattern is over-mocking. When systems are heavily mocked, tests validate artificial environments rather than real behavior. APIs respond instantly, databases never fail, queues process perfectly, and timeouts never happen. Production systems rarely behave this cleanly.
“A passing test suite can still describe a system that has never faced reality.”
This is why some teams discover severe issues only after deployment, even though every automated test passed successfully before release.
This problem appears frequently in teams that aggressively optimize for coverage thresholds. Developers sometimes write tests that execute functions simply to increase percentages without validating meaningful outcomes.
For example, a recommendation engine may have complete branch coverage because every algorithm path executes during testing. However, if the assertions only check that the function returns “some value” instead of verifying recommendation quality, severe ranking bugs may still reach production unnoticed.
The test suite appears healthy while the user experience quietly deteriorates.
Why Bugs Still Reach Production Despite High Coverage
Software failures usually happen at the boundaries between systems, not inside isolated functions. Unfortunately, traditional coverage metrics rarely capture these interactions effectively.
Business Logic Failures
Many critical bugs are not technical failures. They are logic failures.
A pricing engine may technically execute every branch correctly while applying the wrong tax rule for a specific region. A subscription system may incorrectly renew discounted plans. An onboarding flow may skip compliance checks under rare conditions.
Coverage cannot determine whether business intent was preserved.
Integration Failures
Modern applications depend on external systems constantly. APIs, authentication services, payment providers, analytics platforms, notification services, and cloud infrastructure all introduce unpredictable behavior.
Unit tests with mocked dependencies often fail to capture:
- API schema changes
- Timeout handling
- Retry logic failures
- Rate limiting behavior
- Serialization inconsistencies
- Network instability
These failures frequently appear only in staging or production environments.
Concurrency and Timing Problems
Some of the hardest bugs to detect are timing-related.
Race conditions, asynchronous failures, cache invalidation issues, and distributed system inconsistencies may never appear during standard automated testing. Yet they can become catastrophic under production traffic.
Coverage metrics provide almost no visibility into these risks because execution alone cannot validate timing behavior.
Device and Environment Variability
Applications rarely operate in controlled environments.
Mobile apps face device fragmentation, low memory conditions, battery optimizations, interrupted connectivity, and OS-specific behavior. Web applications behave differently across browsers, extensions, and rendering engines.
A test suite running on a stable CI environment cannot fully simulate these conditions.
This is one reason why production monitoring and observability are just as important as automated testing.
The Difference Between Testing Code and Testing Systems
A major shift in engineering maturity happens when teams stop viewing software as isolated code units and start treating it as an interconnected system. Early-stage testing strategies often focus heavily on individual methods, functions, and classes because they are easier to validate in controlled environments. While this approach improves local correctness, it does not necessarily guarantee that the entire application behaves reliably once all moving parts interact in production.
Unit tests remain extremely valuable because they validate individual components quickly and efficiently. They provide rapid feedback during development and help teams catch regressions before changes spread deeper into the system. However, real-world applications rarely fail because a single isolated function behaves incorrectly. Failures usually emerge from interactions between services, infrastructure layers, dependencies, browsers, networks, and user workflows operating together under unpredictable conditions.
A login function, for example, may pass every unit test successfully while the complete authentication flow still breaks in production. Session storage may fail under load, authentication tokens may expire incorrectly, cookies may behave differently across browsers, load balancers may interrupt requests, or third-party identity providers may change their response structure unexpectedly. In all of these situations, the isolated code technically works, but the system as a whole becomes unreliable.
This is why mature engineering organizations rely on layered testing strategies instead of depending exclusively on unit-level validation. Different forms of testing solve different reliability problems, and no single testing layer provides complete confidence on its own.
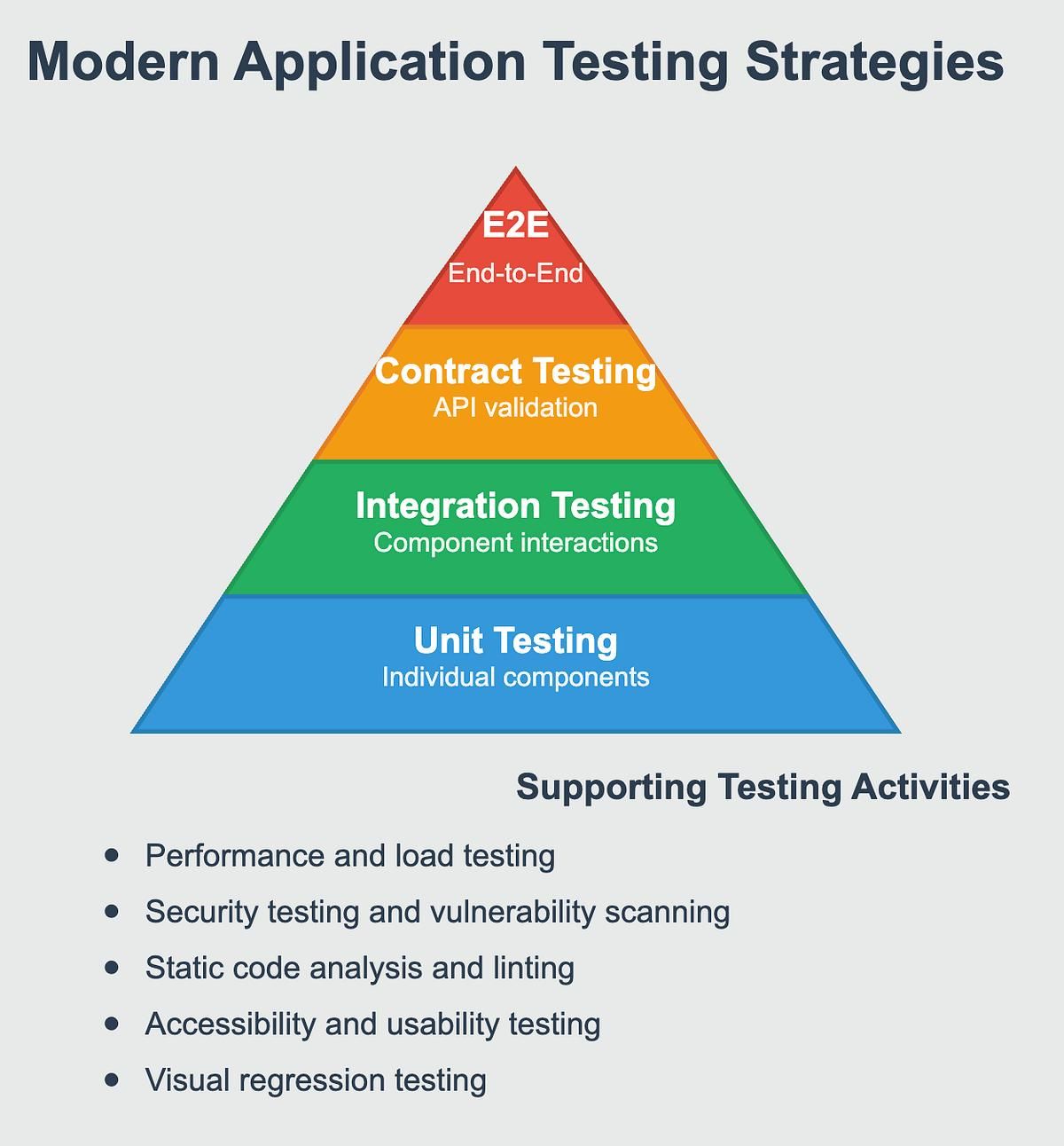
| Testing Layer | Primary Purpose |
|---|---|
| Unit Testing | Validates isolated logic and functions |
| Integration Testing | Verifies interaction between components |
| End-to-End Testing | Validates complete user workflows |
| Exploratory Testing | Discovers unexpected behavior manually |
| Performance Testing | Measures scalability and stability |
| Chaos Testing | Evaluates resilience during failures |
The most reliable systems are built by teams that understand testing as a spectrum rather than a single activity. Confidence emerges when multiple testing layers work together to validate both correctness and resilience under realistic conditions.
What Actually Matters More Than Coverage Percentage
Coverage percentage alone is a weak quality signal because it says very little about how effective the tests actually are. A system with 95% coverage can still contain serious production risks if the tests only validate superficial behavior. On the other hand, a system with lower coverage may be far more reliable if its tests focus on critical workflows, edge cases, and failure handling.
Strong engineering teams focus less on percentages and more on practical confidence. The important questions are whether tests can detect regressions reliably, validate business-critical workflows, and handle real-world instability. These factors reveal far more about software quality than a coverage dashboard ever can.
The best test suites usually validate behavior instead of implementation details. Internal code structures change frequently during refactoring, but user-facing behavior should remain stable. Tests tightly coupled to implementation often become brittle and expensive to maintain, while behavior-focused tests remain useful even as the system evolves.
Reliable testing strategies also validate failure conditions, not just successful paths. Production systems constantly face invalid inputs, dependency outages, retry failures, corrupted data, and partial degradation. Software quality is not only about whether the system works under ideal conditions. It is also about how gracefully it behaves when things go wrong.
Most importantly, effective tests reflect real user behavior. Users refresh pages unexpectedly, switch devices midway through workflows, operate on slow networks, and interact with applications unpredictably. Tests that simulate realistic usage patterns provide far more confidence than tests built only around controlled happy paths.
Risk-Based Testing
Not every component in an application carries the same business risk, yet many testing strategies treat all code as equally important. This creates inefficient allocation of engineering effort because teams spend valuable time heavily testing low-impact functionality while potentially under-testing high-risk systems.
Risk-based testing addresses this problem by prioritizing testing effort according to business impact and failure probability. Instead of attempting to maximize universal coverage equally across the application, teams focus on areas where failures would create the most significant operational, financial, or customer-facing consequences.
| Risk Factor | Core Question |
|---|---|
| Probability | How likely is this area to fail? |
| Impact | How severe would the failure be? |
A visual bug in a rarely visited settings page may be inconvenient, but it is unlikely to create major business damage. A payment processing bug, authentication issue, or compliance failure, however, can immediately affect revenue, security, customer trust, and operational stability. Treating both categories with identical testing intensity rarely makes sense.
This approach allows engineering teams to prioritize revenue-critical workflows, security-sensitive systems, high-traffic application paths, compliance-related functionality, frequently changing modules, and historically unstable components. Testing effort becomes aligned with business risk rather than arbitrary coverage goals.
“The goal is not to test everything equally. The goal is to reduce meaningful risk.”
Risk-based thinking also improves development velocity because teams stop over-investing in low-value test maintenance while strengthening validation around the areas that truly matter.

Better Ways to Evaluate Test Quality
Coverage should not be discarded entirely because it still provides useful visibility into untested areas of a codebase. Extremely low coverage may indicate weak testing discipline or insufficient validation practices. However, coverage becomes problematic when organizations treat it as the primary indicator of quality instead of one diagnostic signal among many.
Several alternative indicators provide much stronger insights into testing effectiveness.
Mutation testing is one of the clearest examples. In mutation testing, application logic is intentionally modified to determine whether the test suite detects the change. If tests continue passing despite altered behavior, the suite may have high coverage while still failing to validate meaningful correctness. This approach measures whether tests are actually capable of detecting defects rather than simply executing code paths.
Another valuable metric is defect escape rate, which measures how many bugs still reach production despite testing efforts. This often reveals far more about engineering quality than coverage reports. A team with lower coverage but consistently fewer production incidents may actually possess a stronger and more effective testing strategy than a team reporting near-perfect coverage while still experiencing frequent outages.
Modern reliability engineering also places heavy emphasis on operational responsiveness. Strong systems are not only systems that avoid failure. They are systems capable of detecting, isolating, and recovering from failures quickly. This is why observability practices such as monitoring, logging, tracing, and intelligent alerting have become central components of software quality engineering. Testing does not end at deployment. Reliability continues through production visibility and incident response capabilities.
The Role of Exploratory Testing
Automated testing provides consistency, speed, and scalability, but automation fundamentally follows predefined instructions. Exploratory testing introduces human curiosity into the quality process, allowing teams to uncover problems that scripted automation may never discover.
Human testers often identify issues by intentionally behaving unpredictably. They misuse workflows, attempt confusing navigation paths, observe emotional friction during interactions, notice visual inconsistencies, and interact with systems in ways that developers did not originally anticipate. These discoveries frequently expose usability issues, workflow confusion, and unexpected edge cases that automated suites overlook entirely.
This becomes especially important in consumer-facing products where user trust and retention depend heavily on experience quality. A workflow may technically function correctly while still creating enough friction to frustrate users or reduce conversion rates. Automated tests rarely capture this kind of experiential problem effectively.
Exploratory testing therefore complements automation rather than competing with it. One provides scalability and repeatability, while the other provides creativity and unpredictability.
Why Chasing 100% Coverage Can Become Expensive
Pursuing perfect coverage also introduces significant maintenance costs over time. As coverage targets become increasingly aggressive, engineering teams often begin writing tests for low-value code paths that contribute little actual reliability improvement. The result is frequently a larger, slower, and more fragile test suite.
Over time, excessive testing overhead can slow CI/CD pipelines, increase debugging effort, discourage refactoring, produce flaky behavior, and reduce overall developer productivity. Teams may spend more time maintaining brittle tests than improving the application itself.
This creates an important engineering tradeoff. Beyond a certain point, the cost of additional testing may exceed the practical reliability benefit it provides. Mature teams recognize that testing is not about maximizing quantity indefinitely. It is about maximizing confidence efficiently.
The strongest testing strategies therefore balance reliability, speed, maintainability, and operational value instead of optimizing blindly for percentage targets.
Building a Smarter Testing Strategy
Strong testing strategies combine multiple quality approaches rather than depending on a single metric or methodology. Coverage still has value as a visibility tool for identifying untested areas, but it should guide investigation rather than define success.
Effective teams prioritize high-risk workflows, validate real user behavior, test failure handling aggressively, invest heavily in observability, combine automated and exploratory testing, and continuously learn from production incidents. This creates a feedback loop where real-world system behavior improves future testing strategies over time.
Most importantly, mature engineering organizations understand that testing is fundamentally about reducing uncertainty rather than achieving mathematical perfection. Software quality cannot be compressed into a percentage on a dashboard because reliability emerges from understanding how systems behave under realistic operational conditions.
Coverage can indicate activity. Meaningful testing creates confidence.
Conclusion
100% test coverage often creates the illusion of safety, but software quality cannot be reduced to a percentage on a dashboard. Coverage only tells teams that code was executed during testing. It does not guarantee that workflows behave correctly, integrations remain stable, or systems can survive real production conditions.
The real danger of high coverage is misplaced confidence. Teams sometimes optimize for coverage metrics instead of testing meaningful behavior, failure scenarios, and high-risk workflows. As a result, applications with excellent coverage reports can still experience critical production bugs, outages, and broken user experiences.
Reliable software is built through layered testing strategies, realistic scenario validation, observability, and continuous learning from production incidents. Strong engineering teams focus less on proving that every line ran and more on understanding how the system behaves when users, infrastructure, and dependencies become unpredictable.
Coverage is still useful, but only as a diagnostic signal. It should guide conversations about risk and testing gaps, not act as proof of correctness.
Because ultimately, users do not care how much code was covered. They care whether the product works consistently when it matters most.
Ready to ship in-app experiences without waiting on releases?